
Initialement l’article devait s’intituler: « simulation: une technique scientifique à utiliser avec des pincettes ». Mais il faut reconnaître que le titre actuel est plus accrocheur. Rien de mieux pour aborder un sujet qui me tient à cœur: la simulation informatique… et ses limites.

Rien de plus amusant que de feuilleter des revues de vulgarisation scientifique d’il y a quelques années. On revoit les technologies qui, à l’époque, nous étaient présentées comme révolutionnaires. On y retrouve les certitudes qu’en l’an 2000, tout le monde aura ceci ou cela dans son quotidien. On y glane des photographies avec les supercalculateurs de l’époque dont la puissance équivaut à celle de l’iPad actuel et qui prenaient un volume de trois pièces. On y apprend par exemple qu’en 1993 « France Télécom va investir au Japon pour y développer le Minitel ». En rigolant doucement car en 1994 j’avais ma première adresse mail et utilisait ce qu’à l’époque on appelait un « butineur ». En 1996 Internet avait suffisamment explosé pour que Sciences & Avenir lui consacre un dossier en nous précisant les codes (sic) à rentrer (en réalité les simples adresses http://…). Pareillement, tous les futurs remplaçant du Concorde qui voleront à mach 2 ou 3 en 2010 nous étaient présentés… On s’y marre également en revoyant les prévisions et autres simulations qui sont rarement dans les clous, 20 ans après. De manière générale on s’aperçoit que les prévisions concernant le progrès technique sont toujours trop pessimistes à court terme et trop optimistes à long terme.
Je prendrai pour exemple les années 1990 qui ont été marquées par une prise de conscience environnementale initiée par le problème de la couche d’ozone et l’accident de Tchernobyl. La découverte d’un possible accentuation de l’effet de serre entraînant un réchauffement global du climat a fortement animé le sommet de la Terre à Rio[1]. Admirons les prévisions de l’époque sur le réchauffement du climat qui nous donnaient de très inquiétants +5 à +10 degrés sur l’Europe entre 1990 et 2010-2020. Cela impliquait une certaine augmentation du niveau des mers[2]. Suffisante pour engloutir une grosse partie des Pays-Bas (il suffit d’un mètre pour ce faire).
Ce n’est pas vraiment la sonnette d’alarme qui était tirée, mais plutôt le bourdon de 13 tonnes. Dans cette folie de prédictions désastreuses gravitaient (et gravitent toujours d’ailleurs) d’éminents scientifiques (qui 20 ans avant nous prédisaient un refroidissement généralisé impliquant famines et migration, comme Paul Ehrlich ), et des genres de gourous qui nous ressortent les fameuses théories Gaïa [3]

Vous trouverez d’ailleurs ici une carte interactive permettant de visualiser la perte des territoires suivant la hauteur de la montée des eaux: carte interactive
Rassurons-nous les prévisions de montée des eaux (montée se chiffrant à quelques mm par an depuis le début du XXème siècle et qu’il n’est nullement question ici de contester), s’établissent maintenant à 42 cm pour le 21ème siècle dans le dernier rapport en date (soit déjà la moitié du rapport précédent).
Je ne résiste pas à l’envie de vous donner le lien vers l’archive du JT d’Antenne 2 datant de 1989 qui annonçait que « dans 10 ans des régions entières auront disparues sous les eaux », on pourra y voir toutes les techniques de choc médiatique si aptes à conditionner le téléspectateur et si fausses scientifiquement.
Je ne m’appesantirai pas plus sur cette parenthèse qui n’était là que pour illustrer le propos qui va suivre, d’autres exemples tout aussi marquants auraient pu être pris: nombre de morts prévisionnels du virus du SIDA (notamment en Afrique), ou de la pandémie grippale, population du globe…etc… toutes ces prévisions se sont gourées magistralement à plus ou moins moyen terme.
Comment fonctionne la science prédictive?
Depuis les années 1980 les prédictions sont effectuées (excepté pour Mme Soleil) par simulation de modèle mathématiques via des calculateurs, ou maintenant des ordinateurs. On y gagne beaucoup en rapidité de calcul et en complexité des paramètres à prendre en compte. Ceci dit l’ordinateur est très bête et ne restitue que ce qui a été demandé. C’est aux scientifiques en phase amont d’effectuer un travail préparatoire le plus complet possible pour établir les paramètres pertinents du modèle mathématique. Là réside la première difficulté.
Un exemple simple
Dans le cadre très physique de la simulation d’un champ électrique émis par un doublet élémentaire, on a une relation mathématique simple de type E=Racine(k*P)/D où E est le champ électrique (en V/m), D la distance par rapport à la perpendiculaire du doublet (en m), P la puissance en Watt appliqué au doublet et k=90, un facteur de la relation puissance-champ suivant la géométrie. A partir de ce doublet élémentaire, on peut construire un modèle de base, qui sera dans ce cas appelé antenne isotrope, c’est à dire rayonnant pareillement dans toutes les directions. Ce genre d’antenne n’existe pas, mais permet de servir de modèle de base à partir duquel toutes les autres antennes vont être étudiées. Dans le cadre de cette antenne isotropique, k sera égale à 60 et, si on recherche le champ mesuré, E efficace (c’est à dire dans ce cas Emax divisé par racine de 2) on aura la relation suivante E=racine(30*P)/D. Aussi pour une puissance de 10W, on aura une mesure de champ de 1,15 V/m à 15 mètres.
caractéristiques du modèle
Sauf que dans la vie, l’électromagnétisme c’est plus compliqué qu’une simple formule. D’abord parce qu’aucune antenne n’est isotrope (d’une part c’est impossible à construire et d’autre part ça n’a pas grand intérêt), elles ont chacune un modèle de rayonnement qu’on appellera diagramme. Celui-ci sera donné en fonction du rayonnement isotrope, un peu comme on calcule une variation de prix en fonction d’un indice 100 à une date donnée. Le diagramme de rayonnement mettra en évidence des directions privilégiées de propagation, des angles d’ouverture…etc… il va donc falloir appliquer un coefficient de correction en fonction du diagramme de rayonnement. Ce sera l’utilité du gain qui servira en quelque sorte de coefficient multiplicateur.

diagramme de rayonnement d’une antenne
Nous avons donc vu la première difficulté qui est de caractériser l’antenne par rapport à un modèle élémentaire existant. Mais il en existe bien d’autres comme nous allons le voir.
Influences pertinentes
En théorie il n’y a pas de différence entre la théorie et la pratique, en pratique, si.
Une fois le modèle plus ou moins caractérisé, il convient de se poser la question des paramètres extérieurs pouvant influencer le résultat. Le scientifique doit déterminer (et justifier) si ces influences peuvent être considérées comme négligeables ou pas. Suivant les situations, seront considérées comme négligeables des contributions inférieures à un dixième, ou un centième, ou encore un millième. C’est le protocole qui décidera.
Pour recenser les influences, on pourra utiliser la méthode d’Ishikawa. Il conviendra de pouvoir quantifier leur importance. Dans le cadre de l’exemple de la propagation du champ électromagnétique, on pourra s’intéresser à différents phénomène physiques connus comme la diffraction, la diffusion, les réflexions multiples et les atténuations qui correspondent au milieu. Sans entrer dans les détails, on se doutera que les bâtiments par exemple, pourraient créer des obstacles atténuant le signal, de même que la pluie ou le brouillard influencent la propagation. Dans le cadre d’une transmission à haute fréquence de courte distance, on pourra supposer que l’activité solaire ou l’état de l’ionosphère n’a que peu d’influence, ce qui ne sera pas le cas par exemple pour les liaisons de plusieurs milliers de kilomètre avec un sous marin en fréquence plus basse.
Notez également que pour quantifier ces phénomènes d’interaction, on fait appel à des modèles théoriques qu’on aura aussi simulé ce qui peut donner un aspect « poupées russes » aux prédictions.
Domaine de validité
Revenons à notre antenne, vous êtes tous prêts maintenant à nous donner le champ électrique à 25 cm de celle-ci si je vous donne les informations suivantes:
puissance d’entrée 10W
gain (décimal) dans la direction mesurée (en champ): 2,1
influence environnementale de la propagation très faible: 0,99
jetés sur vos calculettes vous me donnez: 144 V/m en me disant que vous avez réussi à prédire le niveau de champ électrique au point donné (sisi je vous entends encore).
Sauf que c’est faux. Votre calcul est sans doute bon, mais le résultat est faux. Tout simplement parce qu’on a oublié un truc essentiel quand on utilise des formules: leur domaine de validité.



Le domaine de validité pour des lignes haute tension n’est pas le même que pour des semi-conducteurs ou des antennes: pourtant il s’agit de champ électromagnétique à chaque fois.
C’est extrêmement important parce que les formules physiques ne se manipulent pas n’importe comment et qu’elles correspondent toujours à des référentiels parfaitement définis. Ainsi, dans le cas qui nous préoccupe, la formule de base n’est valable qu’en zone de champ lointain, c’est à dire à partir d’une certaine distance de l’émetteur. Distance donnée par des formules impliquant la taille, la géométrie et la fréquence de l’émetteur. Et c’est la première question qu’on doit se poser quand on se lance dans les calculs: les formules utilisées sont-elles dans leur domaine de validité?
Premier résumé
De notre petit exemple technique on pourra retenir que les études prédictives:
- se fondent sur un modèle élémentaire qui sera caractérisé puis démultiplié ou agrandi (par exemple par la méthode des éléments finis)
- nécessitent de connaître tous les paramètres influents et de pouvoir les quantifier
- nécessitent de vérifier la validité des formules utilisées avec le domaine d’utilisation à chaque étape du processus
On voit déjà poindre les difficultés pour simuler correctement des comportements assez bien définis. Cela ne nous rassure pas concernant des comportements globaux qui ne possèdent pas véritablement de formule magistrale (température moyenne du globe par exemple). Dans certain cas, la formule est crée de toute pièce en utilisant les statistiques ou l’empirisme.
Mais il reste encore de nombreuses choses qui vont influencer le résultat.
Autres choses à considérer
« Plus que je veux être précis, plus que ça risque d’être faux »
C’est l’adage de toute équipe planchant sur des simulations. Plus vous cherchez la précision, plus vous avez une chance d’oublier un paramètre influent, plus vous risquez d’avoir la certitude que le résultat est faux. Avec 5 décimales derrière. Mais faux. Il convient toujours de caler son désir de précision avec le besoin réel et les capacités de mesures. Devant répondre à un gros client institutionnel pour de la simulation, j’ai simplifié au maximum les processus de calcul dans un logiciel développé en partenariat avec le laboratoire de physique d’une grande école. D’autres logiciels existaient, mais coûtaient très chers, nécessitaient 6 mois de formation et surtout nécessitaient d’entrer des données hyper complètes que le client ne maîtrisaient même pas. A part pour faire joli et se la péter, je ne voyais l’intérêt. La plage utile de précision du client étant assez grande, on pouvait simplifier un maximum les hypothèses rendant négligeables de nombreux paramètres sur lesquels nous n’avions aucune information.
En résumé, plus le phénomène est complexe et interdépendant avec d’autres, plus la précision est difficile à obtenir et plus vous risquez de donner des résultats faux.
Et la plage d’incertitude alors?
Ça c’est un truc qui m’énerve au plus au point: on vous donne un résultat ou une valeur mais avec aucune estimation de l’incertitude associée. C’est pourtant essentiel pour comprendre les données! Les calculs d’incertitude sont très complexes et nécessitent un raisonnement exempt d’erreurs. C’est un peu comme les sondages: on ne vous donne pas les variations possibles en omettant sciemment de préciser que le 24% c’est à plus ou moins 2%…
Normalement tout résultat issu de travaux scientifique est toujours donné avec l‘incertitude liée à son intervalle de confiance. Ce sont les media, les chargés de com’ politique et les charlatans qui omettent systématiquement ces données. Il est vrai que la présentation alourdit la communication, complexifie les chiffres et du coup, entrave la bonne réception du citoyen qui a le QI proche de l’huître (on a des exemples qui sans cesse viennent sonner à la porte de Disons): ainsi une incertitude pourra être donnée en % dans un intervalle de confiance de 95% (c’est généralement la norme). C’est à dire qu’on a 95% de chance que le résultat final soit compris dans l’intervalle donné (24 plus ou moins 2% par exemple) [4]. Bon, avez-vous seulement souvenir d’avoir vu, dans ces publications qui égaient leurs articles d’estimations ou de simulations, une seule donnée concernant l’incertitude des résultats fournis?
L’incertitude en terme de com’ ce n’est pas sexy. Ça laisserait croire qu’on pourrait se tromper, ça insinue le doute alors que la communication doit être efficace et apporter l’adhésion. En terme de com’ ça permet également de ne fournir que le donnée la plus pessimiste (par exemple le niveau des mers montera entre 0,55m et 2m75 en 100 ans, les communicants ont tout intérêt à ne donner que le chiffre le plus élevé); ou le plus optimiste (les prix ne devraient augmenter que de 2,3% cette année…). De même l’incertitude donnée est un excellent moyen pour les scientifiques de critiquer éventuellement le résultat ou la méthode, et exige des justifications que certaines équipes ne sont pas forcément prêtes à donner. Évidemment, plus il y a de paramètres entrant en compte dans le résultat, plus l’incertitude sera complexe à déterminer [5]. Il m’est arrivé d’avoir des simulations avec des incertitudes proches de 100%, ce qui peut paraître insensé dans certains domaines, mais parfaitement viable dans d’autres.
Le biais idéologique
C’est un sujet tabou dans le domaine de la science mais il existe. Vous serez amenés à favoriser les résultats qui vont dans le sens de votre opinion. Il existe évidemment différents degrés, conscients ou non. Par exemple vous pourrez, à travers des milliers de valeurs brutes obtenues, mettre en place une représentation favorisant les valeurs que vous estimez remarquables. Dans les cas extrêmes, vous pouvez même agir sur les algorithmes pour qu’ils fournissent ce que vous désirez. La pratique est très difficile à évaluer et je ne voudrais pas vous faire croire qu’elle est généralisée, mais juste qu’il est difficile d’effectuer ce genre de travail sans avoir une idée sur le résultat final. Cette envie du résultat peut d’ailleurs être bénéfique. Devant effectuer une simulation, j’obtins des résultats qui ne correspondaient pas vraiment à ce à quoi je m’attendais. Bref la simulation contredisait mon sentiment initial. En reprenant les algorithme, je me suis rendu compte de l’erreur d’inversion de phase sur un paramètre. En rectifiant ceci, j’obtins le résultat final réaliste (et conforme à mes sentiments), qu’on a pu valider sur le terrain par la suite. Que serait-il passé si je n’avais pas eu d’idée préconçue au départ? Aucune remise en question du résultat certainement.
Un exemple de biais idéologique post-traitement sur la présentation des résultats (donc réalisable par les communiquant et les relais médiatiques). Il concerne la température du globe, suivant l’année de référence, il est aisé de déclarer que:
- La température baisse
- La température stagne
- La température augmente
- La température augmente très vite
Ce sont pourtant les mêmes données, relevées par satellite et tout à fait valables [6]
Le problème de la réaction en chaîne
Une difficulté supplémentaire dans la simulation prédictive concerne les éléments à tiroirs insérés dans les boucles de calculs. Quand nos résultat à l’itération n dépendent du résultat obtenu à l’itération n-1, lui même dépendant du n-2 …etc… C’est particulièrement vrai quand on recherche une évolution temporelle. Par exemple le nombre de personnes touchées par une pandémie à l’instant t sera fonction du nombre de personnes contagieuses à l’instant t-1 et donc du nombre de personnes touchées par la pandémie…etc… De même que le réchauffement possible des molécules dépend également de leur état n-1 et de leur température précédente pour avoir un gradient acceptable. Pareillement, la simulation de la population à l’année +50 dépend énormément du résultat de la simulation de la population à l’année +25…
Vous comprenez bien que la moindre erreur ou incertitude sur les premiers degrés de l’itération, va, par réaction en chaîne, rendre le résultat final complètement faux et aberrant. Ayez donc à l’esprit ce petit grain de sable dans une huître qui va, a fil des années, se faire enrober de matière pour devenir, bien plus tard, une belle et grosse perle.
En conclusion
Nous avons vu que les simulations procédaient par mis en place d’un modèle élémentaire caractérisé parfaitement que l’on démultipliait tout en maîtrisant les paramètres influents et les domaines de validité des formules. Les limites de la prédiction, outre le fait de ne pas se tromper sur la caractérisation du modèle, concerne différents facteurs, comme la précision inadaptée, l’intervalle de confiance et le biais idéologique. Enfin, dans le cadre de simulation où les modèles sont interdépendant et calculés de manière itérative, toute imprécision initiale se retrouve amplifiée, faussant tout résultat.
Le doute est donc indispensable quand des estimations ou des simulations vous sont présentées. Non pas le doute bête, idéologique et confortant, mais le véritable doute scientifique qui exclut par exemple tout complot pour s’intéresser à la validité , la pertinence des résultats et surtout, de leur présentation. Si la science a fait d’énorme progrès dans le domaine de la simulation, il n’en reste pas moins que l’homme est faillible, ce que la machine ne sait pas!
————–
[1] Ce qui est amusant c’est qu’à relire la littérature de l’époque, le méthane et le CO2 étaient tous les deux accusés de participer à l’effet de serre. Et le méthane bien plus (4 fois plus problématique). Entre temps, la planète entière se sera focalisée sur le CO2, bizarrement depuis l’invention des bourses et crédits carbone par des spéculateurs très avisés et qualifiés d’écologistes. Le méthane a donc disparu opportunément des principales préoccupations.
[2] La montée du niveau des mers n’est pas due à la fonte de la banquise du Pôle Nord, ni même à la fonte des glaciers terrestres mais principalement due à la dilatation consécutive à la hausse de la température. Aussi le calcul est particulièrement dépendant de la précision du paramètre de la température globale moyenne des eaux du globe.
[3] Qui considère que la Terre est un organisme vivant dont l’Homme serait un virus. Ne rigolez pas cette théorie a de nombreux adeptes et nombreux relais.
[4] A ce propos je me souviens avoir passé des heures à essayer de faire comprendre à un citoyen « à qui on ne la fait pas et qui s’interroge » ce qu’était un intervalle de confiance à 95% car il estimait (et ça l’arrangeait) que c’était l’incertitude qui était de 95%
[5] Pour simplifier l’incertitude peut être vue comme la somme quadratique des incertitudes élémentaires de chaque paramètre combinées avec leur loi de distribution probabiliste et le coefficient de l’intervalle de confiance.
[6] Qu’il est intéressant de comparer avec les simulations effectuées à la fin des années 1990 qui nous sont toujours proposées (on s’aperçoit que la période 2000-2010 est totalement fausse…):
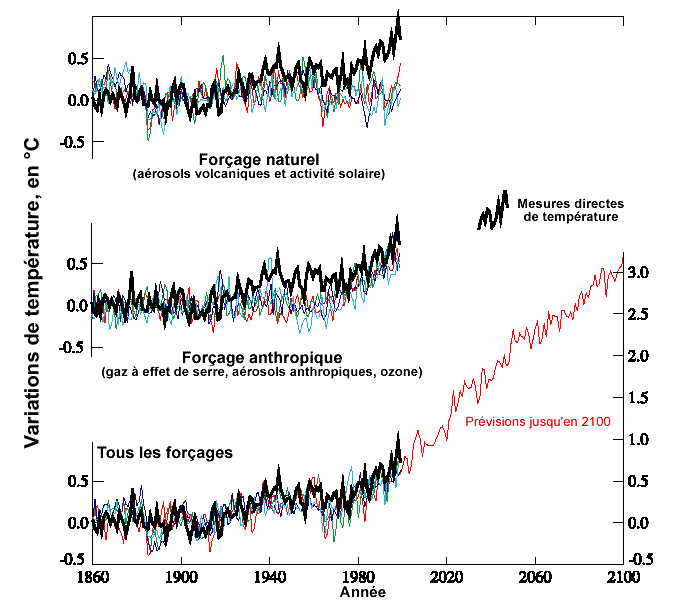

Pour info la variation de température du globe amenant les scientifiques dans les années 1970 à imaginer une prochaine glaciation:
Mais si les Pays-bas disparaissent que vont devenir tous ces pauvres marocains qui y vivent ?
Passionnant !
J’y retrouve complètement mes habituelles réserves quant à la soi-disant intelligence de l’homo auto-déclaré sapiens… Et il n’y a pas que dans le domaine scientifique, mais aussi politique, social, voire amoureux…
Tout l’humain, quoi.
Un peu d’humilité, pas mal de prudence, beaucoup d’honnêteté et énormément de rigueur… et là, on peut espérer faire un usage correct de nos facultés d’intelligence (car il y en a…).
J’aime bcp ton « intro » (parenthèse, dis-tu) qu’on lit le sourire aux lèvres… Tant de prévisions qui « se sont gourées magistralement à plus ou moins moyen terme. » Il y a de quoi rire. (hier, je parlais justement de l’usage manipulateur du « temps futur » des verbes dans la com politique).
Tu fais vraiment le tour de la question de la « prédiction », ce qui est un tour de force tellement c’est complexe. La plupart des prédictions pourraient être améliorées avec plus de rigueur et d’honnêteté, mais je crois que 2 autres terribles contraintes sont presque insurmontables :
• le « biais idéologique », qui est paradoxalement omniprésent dans le domaine scientifique : car il est en grande partie inconscient (ou alors, cela relève de la falsification). Difficile à corriger car on ne le voit pas…
• la « réaction en chaîne ». C’est sans doute le pire obstacle. Tu évoques le « grain de sable » au début du processus, mais il est continuel à tous les moments du processus. Et même sur le moyen terme, avec tant de paramètres interactifs, la succession des événements est absolument imprévisible : ça peut partir dans n’importe quelle direction.
Heureusement que Léon nous a parlé du Jeu de Mail avant que son avenue ne soit engloutie.
oh perso je suis tranquille, même à +13m. Par contre les nudistes du cap d’Agde pourront se reconvertir dans la plongée sous-marine.
Perso 94 mètres.Je rigole
Il y a des jours comme ça , où la Terre entière en veut à Furtif et les jours où Lapa rajoute une pierre sur ma tombe.
.
.
Pourquoi tant de haine?
euh si je dis que k tient compte du couplage entre le champ magnétique et le champ électrique suivant la direction du vecteur de Poynting j’ai gagné quoi?
.
,……… on pourra utiliser la méthode d’Ishikawa…….
Moi j’appelle ça depuis bien plus longtemps que Bonaldi qui me l’a volée.
La loi de l’emmerdement maximum ou la LEM
J’ai pu vérifier son efficience dans l’étude de mon ex femme et de ses rapports avec son sac à main.
Ex : elle ne découvrait jamais son oubli avant que la distance entre notre point de départ et notre situation présente soit supérieure à celle d’avec notre point d’arrivée.
Comme historien je pourrais inventer une image symbolique de ce que font les prédictionnistes.
En 1650 certains d’entre eux ont prédit que les harnais des chevaux seraient entièrement en tissu en l’an 2000 et les fers des mêmes chevaux seraient remplacés par des sabots métalliques .
Exact, comme au XIXème, on imaginait l’an 2000 à la machine à vapeur, car l’électricité et le moteur à explosion n’avaient pas percé!
Moi j’aimerais bien être d’accord avec vous, mais à partir de « un exemple simple » je me suis dit comme Furtif : pourquoi tant de haine envers Léon ?

c’est pas grave Leon, ce qu’il faut surtout retenir de l’exemple est indiqué dans le petit résumé juste après
j’ai essayé d’être vulgarisateur et pas trop incompréhensible pourtant j’ai l’impression que y’a que COLRE qui a accroché
passe qu’il fallait sauter par-dessus E=Racine(k*P)/D… On n’est pas obligé de comprendre l’exemple pour comprendre le nartik.
En gros, je résume pour moi : on peut énoncer n’importe quoi dans un contexte d’apparente rationalité et même dans les sciences « dures », alors que c’est « faux » (question de focale).



Alors, rendez-vous compte dans les sciences humaines…
Et rendez-vous compte chez les truffiers et les mabouls…
Dis-moi, Lapa, je dis souvent que la simulation est un « art »… tu es d’accord ?
Et c’est quoi que tu simules ?
Bon, j’me casse vite fait
Disons que dans les sciences dures, il n’y a que les prédictions qu’on peut énoncer et qui peuvent s’avérer fausses. De manière générale une découverte scientifique et présentée comme telle dans les revues à comité de lecture (même s’il y a des failles) sont supposées justes car répétables et reproductibles et sont directement soumises à la critique de la communauté. La simulation, tant qu’on y est pas… bah difficile de voir où ça coince. Il faut voir que la simulation progresse aussi beaucoup quand elle a la possibilité de se confronter à la réalité. Mais évidemment pour une évolution temporelle, il faut attendre 10 ans pour se rendre compte que le modèle est incomplet ou faux.
Mais ce qui fait surtout dire le n’importe quoi ce ne sont pas les simulations en elles-mêmes, mais souvent la communication à partir de ces simulations. On arrive a des aberrations comme ce Journal d’Antenne 2.
Ceci étant il y a beaucoup de simulations qui sont utilisées dans les processus industriels et ça reste quand même assez fiable. Mais c’est pas de la tarte! De l’art? non je ne pense pas, mais complexe oui.
Alors pendant qu’on y est, et quid des simulations qui ont remplacé les tests réels en matière d’arsenal nucléaire militaire ?
les simulations nucléaires ne sont pas qu’informatiques. Il y a de la modélisation avec des gros lasers il me semble. de toute façon pour être sûr qu’une bombe fonctionne, il faut la larguer ^^
Mais cela nous amène à d’autre type de simulation, par exemple avec des maquettes ou des souffleries…
Bonjour Lapa,
J’ai eu une grosse journée ! Entre les communiqués de presse pour Hervé et mes discussions avec Furtif !
Mais je me suis promis de lire ton article dès que j’aurai le temps, ce qui ne devrait plus tarder.
Bah, Lapa, en tant « qu’économiste », je suis tellement habitué aux prévisions et prédictions foireuses que, en quelque sorte, le problème ne se pose même pas. Quand même tu te situes dans un cadre scientifique, alors l’économie, tu parles !
Nan, je déconne, l’article est intéressant. Mais si je devais faire le même en prenant appui sur la soi-disant « science économique » je ne saurais m^me pas par où commencer. Il y a tout ce que tu dis et beaucoup plus encore. Songeons qu’on n’est même pas foutu de se mettre d’accord sur une définition d’un chômeur, alors…
Salut Lapa.
Très intéressant ton article.
Une question : comment est déterminée la plage d’incertitude ? Par rapport aux données aléatoires je suppose , mais comment sont-elles prises en compte ? (j’espère que la réponse me mérite pas un, voire plusieurs articles )
)
Et re pan sur le museau :
« Pour simplifier l’incertitude peut être vue comme la somme quadratique des incertitudes élémentaires de chaque paramètre combinées avec leur loi de distribution probabiliste et le coefficient de l’intervalle de confiance. »
Bon, sauf que ce n’est pas trop clair
l’incertitude est une science exacte
je vais simplifier sans trop déformer:
chaque paramètre va apporter une incertitude, la méthode en elle-même va apporter une incertitude, bref une fois que tu as déterminé tous les paramètres influençant le résultat (ex: linéarité de la réponse, arrondi, visualisation sur une graduation, température, imprécision de l’appareillage…) tu as des règles pour pondérer ces incertitudes suivant une loi statistique. De manière générale, c’est la loi Normale (fameuse courbe de gauss), mais certaines données sont sur des loi de Poisson par exemple ou autre. Tout cela est connu dans des théorèmes (on n’a rien à redémontrer) donc trouver le coefficient n’est pas bien dur. Et tu fais une somme quadratique (c’est à dire la racine carré de la somme des carrés) de ces incertitudes. La dessus tu obtiens une incertitude totale combinée qu’il va falloir de nouveau coefficienter en fonction de l’intervalle de confiance qu’on veut avoir. Plus l’intervalle de confiance sera grand (99,9% par exemple) plus le coefficient sera élevé donc, plus l’incertitude sera grande.
Exemple dans un intervalle de confiance de 95% on la température suivante: 8°+- 0,5° pour avoir un intervalle de confiance de 99,9% il faudra 8°+- 1° (mis à part le risque nucléaire ^^tous les résultats scientifiques sont généralement donnés pour 95%; mais il y a 66% par exemple)
Si l’on désire que la probabilité, pour que la valeur se trouve à l’intérieur de l’intervalle de confiance , soit égale à 100%, il faut évidemment que cet intervalle soit très large (en toute rigueur, infini). Par contre, si l’on se limite à une probabilité de 95%, l’intervalle de confiance n’aura pas besoin d’être aussi large.
Ainsi, lorsqu’on donne un intervalle de confiance, il faut aussi indiquer la probabilité qu’a notre valeur de s’y trouver. Cette probabilité s’appelle le niveau de confiance.
Le domaine où cette technique est le plus souvent utilisée est la météo .
Plus la projection dans le temps est longue plus les paramètres identiques à la météo pour le lendemain voient leur potentiel de variabilité augmenter suivant une fonction dont Lapa a le secret, mais , j’en ai une idée
Ce n’est pas qu’une discussion de salon ou de DISONS .
L’histoire nous apprend que les jours du Monde furent comptés par ces gens là dans les premiers jours d’un certain mois de juin
Bah, en matière de météo dire que si il ne pleut pas il fera beau (ou gris) reste la meilleure façon de l’annoncer. 8)
D’acc, merci Lapa.
« Vous serez amenés à favoriser les résultats qui vont dans le sens de votre opinion. «
Hmmmm, j’irais même plus loin : vous serez amener à modéliser ce que vous souhaitez trouver », non ?
Pan sur le museau à Ranta : tu l’as écrit deux phrases plus bas
oui y’a toujours le risque conscient ou non.
Quelques questions Lapa, STP :
Comment fait-on pour rentrer et coder des milliers de données ? je veux dire, ça ne se fait pas comme ça, il faut du temps, du monde; de la manière comment peut-on écrire des centaines de milliers de lignes de codes ? Est-ce que vous utilisez souvent des données pré programmées qui sont utilisées pour d’autres types de simulations ? Comment sont choisies les valeurs des éléments aléatoires ?
On utilise l’ouvrier du 21ème siècle qui s’appelle le programmeur et qui tape de la ligne de code. Le nombre de lignes dépendra de la complexité du projet et du langage de programmation. On peut aussi utiliser des outils RAD pour faciliter la programmation (ce sont des genres d’interfaces graphiques pour aider à la programmation). Il y a beaucoup de possibilités en fait. Par exemple le logiciel Aster développé initialement pour EDF et servant pour la mécanique et l’acoustique possède plus d’un million de lignes de code; il est maintenant en licence libre. Ce qui explique le coût de certains logiciels de simulation: souvent pas moins de 100 000 euro la licence pour un produit correct de base…ceci étant je maîtrise pas trop cet aspect; moi dans les projets j’étais utilisateur et prescripteur des algorithmes.
Pour l’aléatoire normalement on évite autant que possible. L’ordinateur a beaucoup de mal à créer un véritable nombre aléatoire (en réalité c’est une formule qu’il faut lui donner et du coup ce n’est plus véritablement aléatoire). On utilise aussi beaucoup les résultats précédents pour lisser les paramètres ou données à rentrer. Quand on a la possibilité de vérifier évidemment…
Bonjour Lapa et bonjour a tous,
excusez pour le commentaire en retard
L’article est excellent et demontre parfaitement les derives du tout modelisation. Dans le domaine des materiaux on en est arrive a un tel point que si les resultats d’experience ne corespondent pas au modele alors l’experience est fausse…
Autrement dit, il y a des gens pour qui la nature doit obeir au modele et non l’inverse.
Bonjour lavabo,
effectivement en cas extrême on peut arriver à des dénis de réalité.
Dans le temporel on peut également avoir le souci suivant: la modélisation fonctionne pour l’instant présent, puis au fil des années on se rend compte d’une dérive, alors on rajoute des facteurs correcteurs sans forcément remettre en question la théorie initiale.